最近几年,AI 的发展真是快得离谱,大家都在关注一个问题:到底哪家模型更强?为此也出现了不少专门做“大模型排行榜”的网站。它们会根据各种评测维度,比如性能、推理速度、成本等,帮我们更直观地看清各个模型的能力分布。
下面整理了一些目前在更新的榜单合集,让对AI感兴趣的小伙伴能看到最新版本的对比,还能顺便了解下行业趋势,看看“谁又卷出了新高度”。
1.LMArena
网址:lmarena.ai/leaderboard
LMArena由加州大学伯克利分校的研究人员创建,是一个开放平台,每个人都可以轻松访问、探索并与世界领先的 AI 模型互动。通过并排比较这些模型并投票选出最佳模型,社区帮助塑造了一个公共排行榜,使 AI 进展更加透明,并扎根于实际应用。
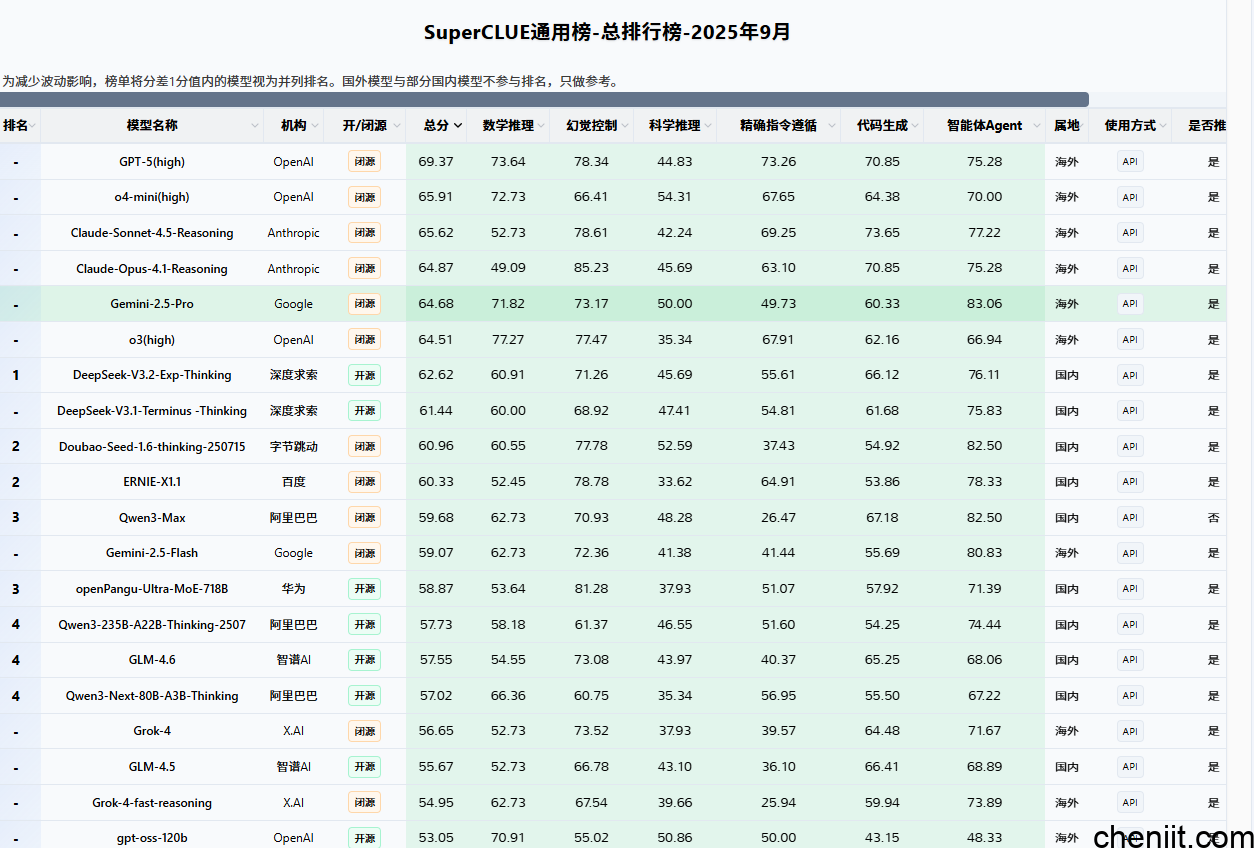
2.SuperCLUE通用榜
网址:superclueai.com/homepage
中文综合评测,涵盖了数学推理、科学推理、代码生成、智能体Agent、精确指令遵循、幻觉控制六大任务,其中数学推理、科学推理、代码生成为推理能力,智能体Agent、精确指令遵循、幻觉控制为应用能力。
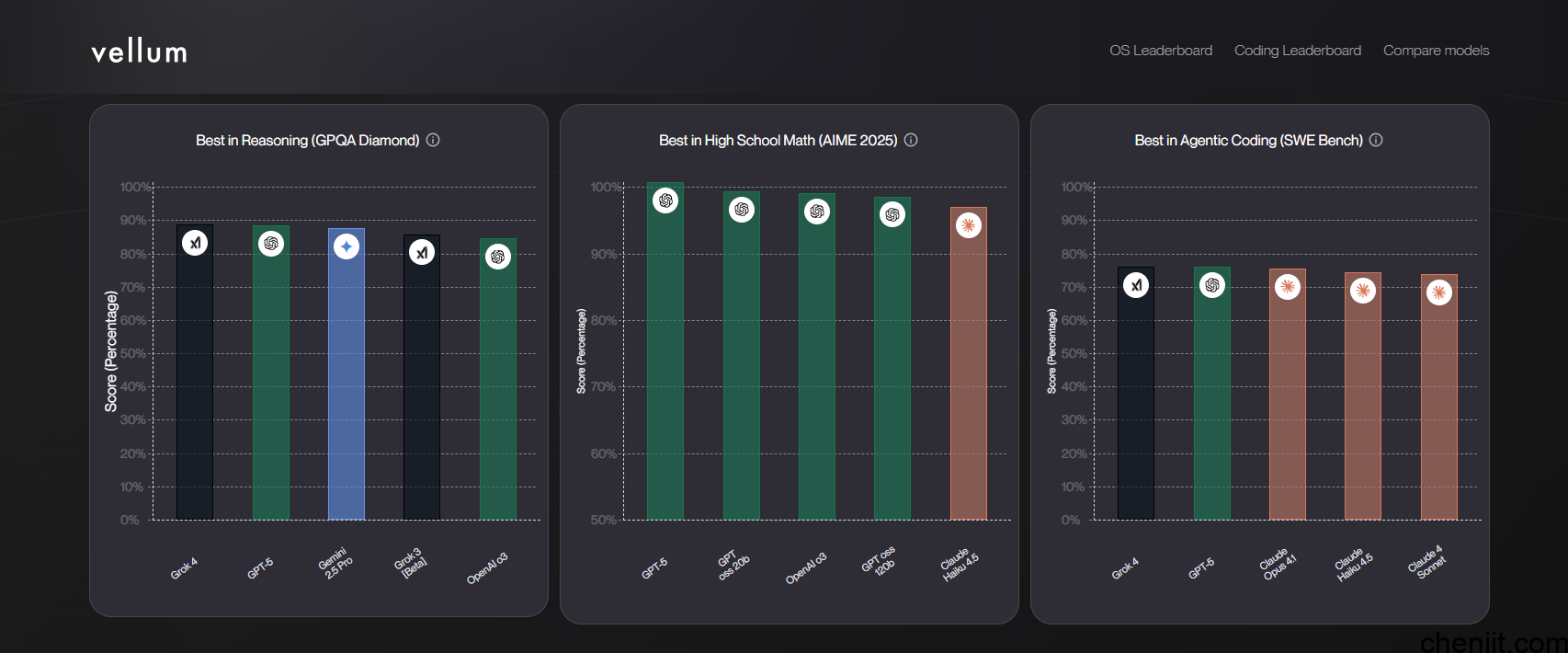
3.Vellum.ai LLM Leaderboard
网址: vellum.ai/llm-leaderboard
简介与特点:跟踪 2024 年 4 月之后发布的最新模型,对比推理能力、上下文长度、成本与精度,包含 GPQA Diamond、AIME 等高难度基准。
4.Open LLM Leaderboard
网址 :vellum.ai/open-llm-leaderboard
简介与特点:由 Vellum 推出的开源榜单,展示社区模型在推理与问题求解任务上的最新表现。
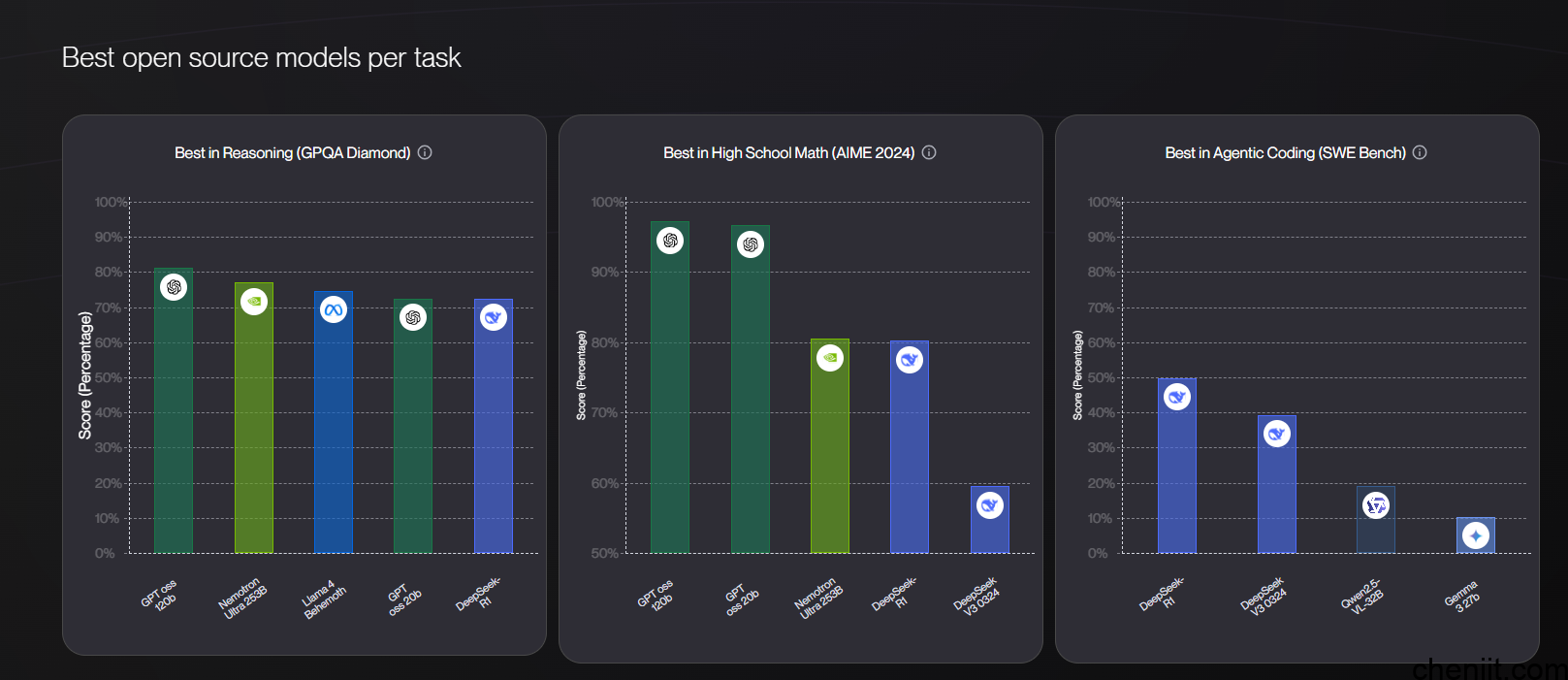
5.LLM-Stats
简介与特点:每日更新,展示模型(如 GPT-5、Grok-4、Gemini 2.5 Pro)的速度、上下文窗口、定价及性能。
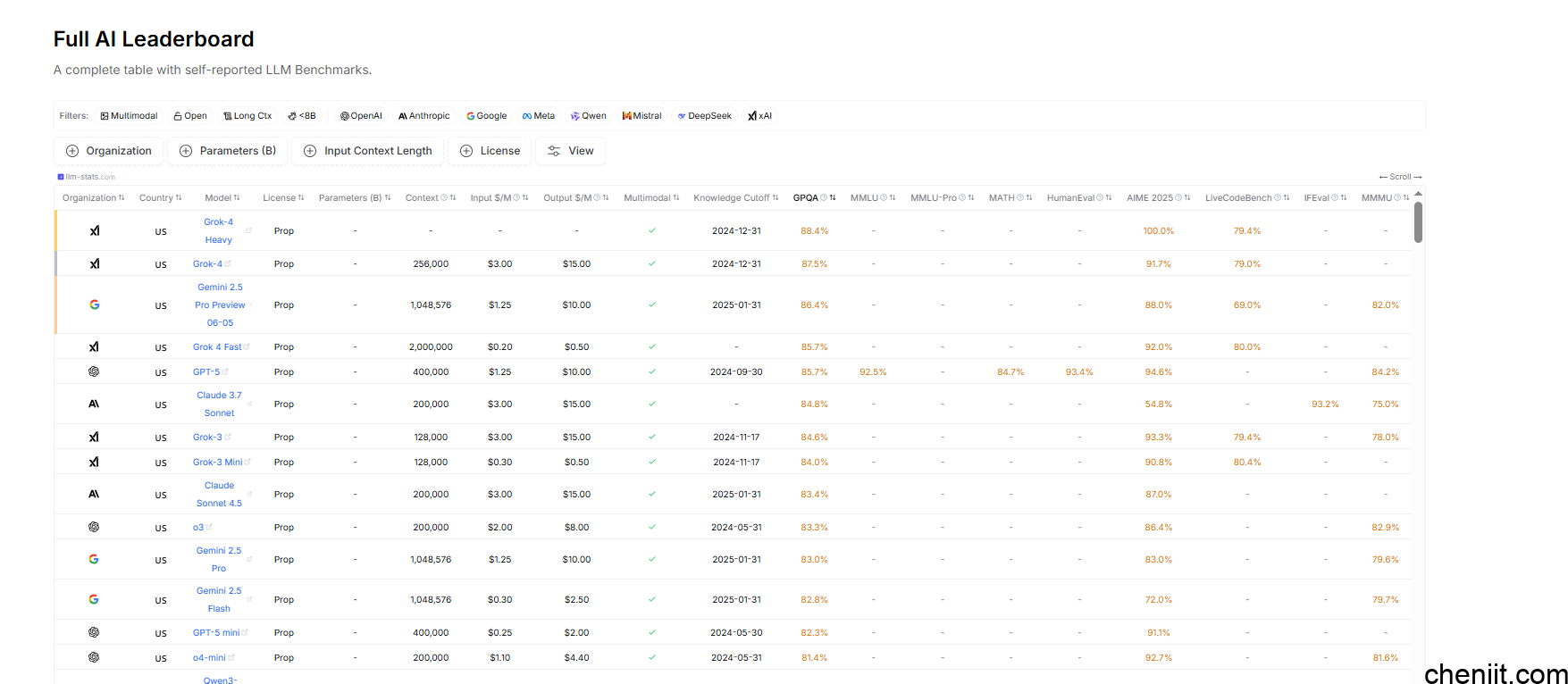
网址:llm-stats.com/benchmarks/llm-leaderboard-full
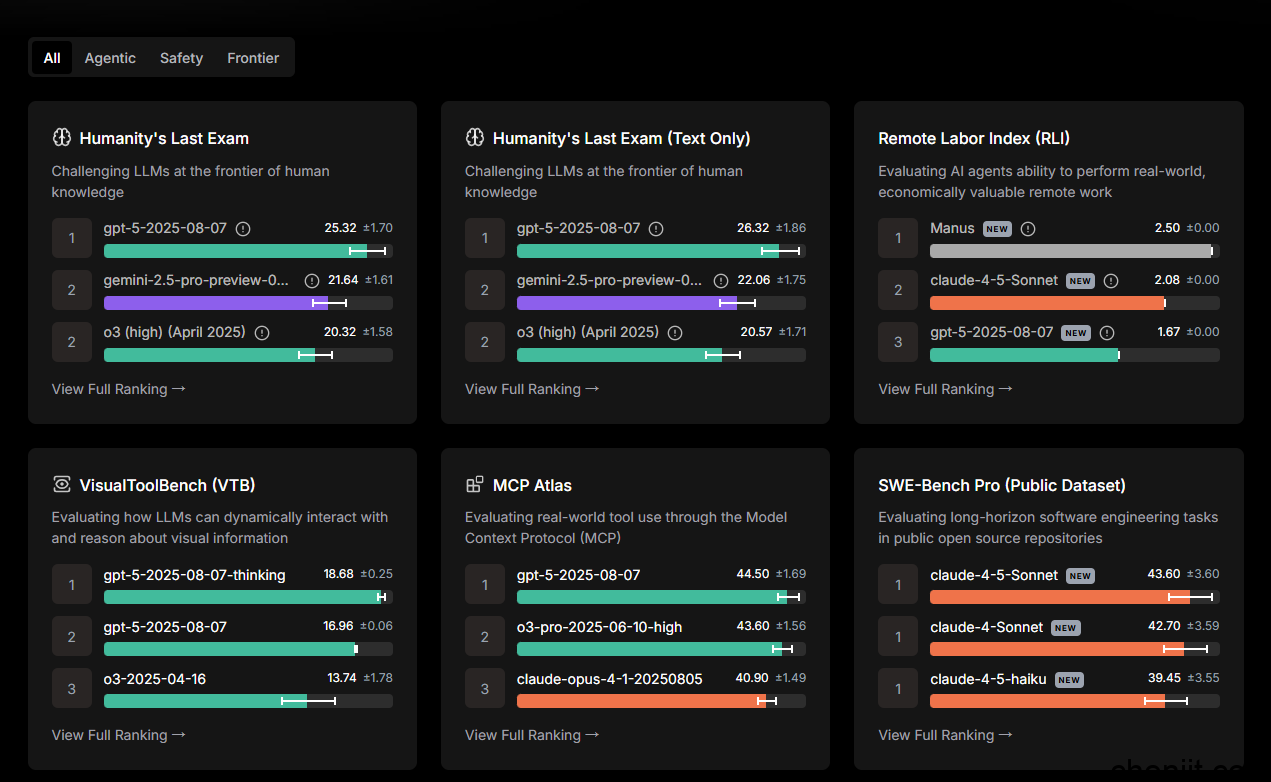
6.Scale AI SEAL
简介与特点:通过私有数据集与专家评审,比较前沿模型在鲁棒性与可靠性方面的差异。
网址:https://scale.com/leaderboard
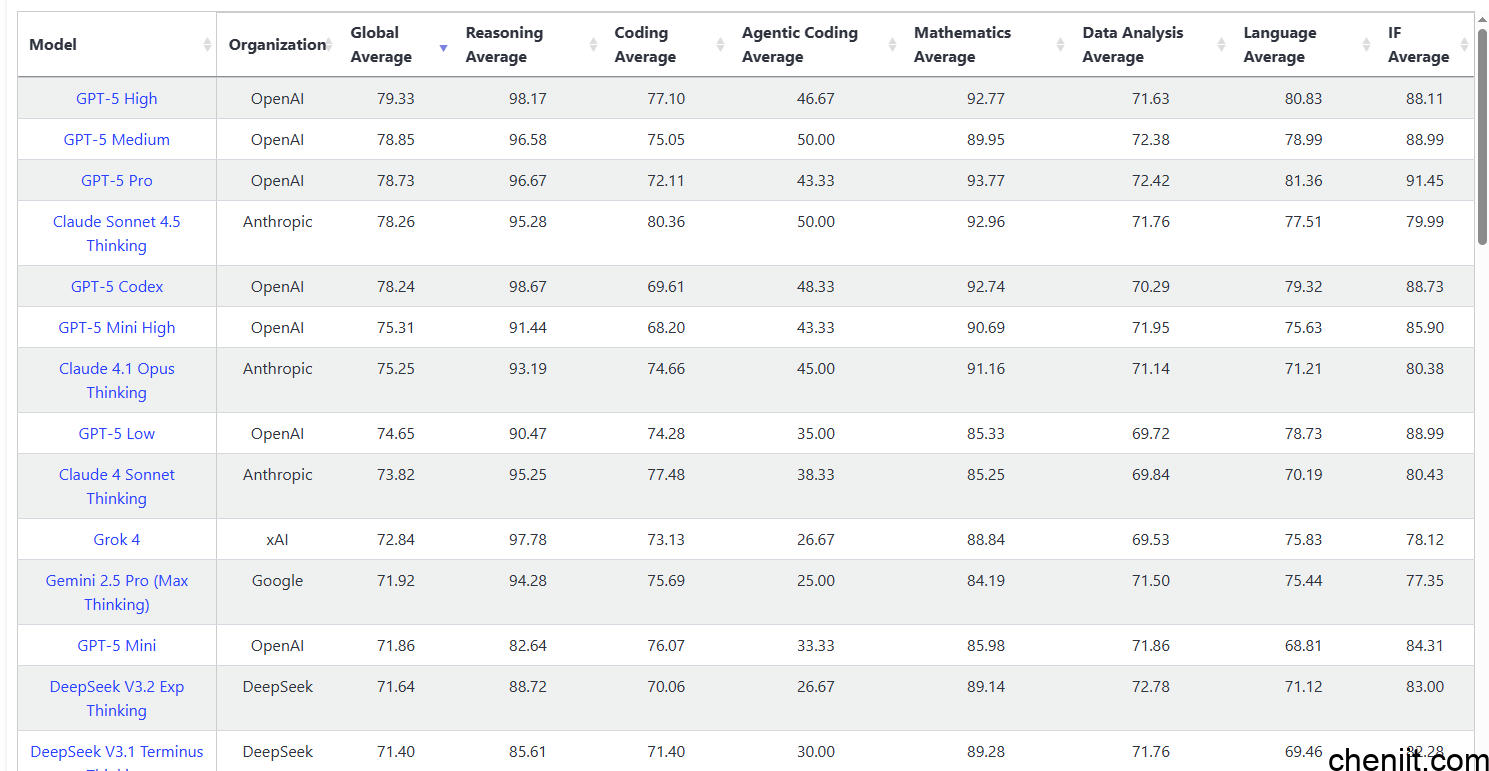
7.LiveBench
简介与特点:每月测试模型,基于“无污染”基准评估推理、编程与数学能力。
网址:https://livebench.ai
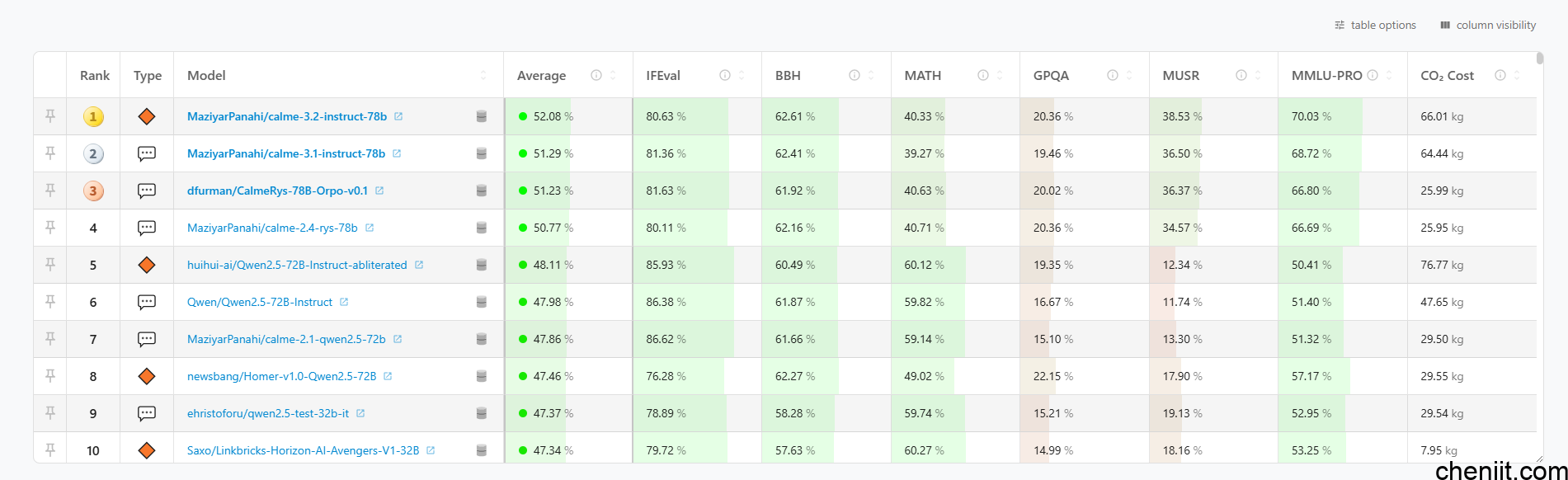
8.Hugging Face Open LLM Leaderboard
简介与特点:使用 EleutherAI 评测框架,对开源模型进行标准化评估,是开源生态的核心榜单。
网址:https://huggingface.co/open-llm-leaderboard
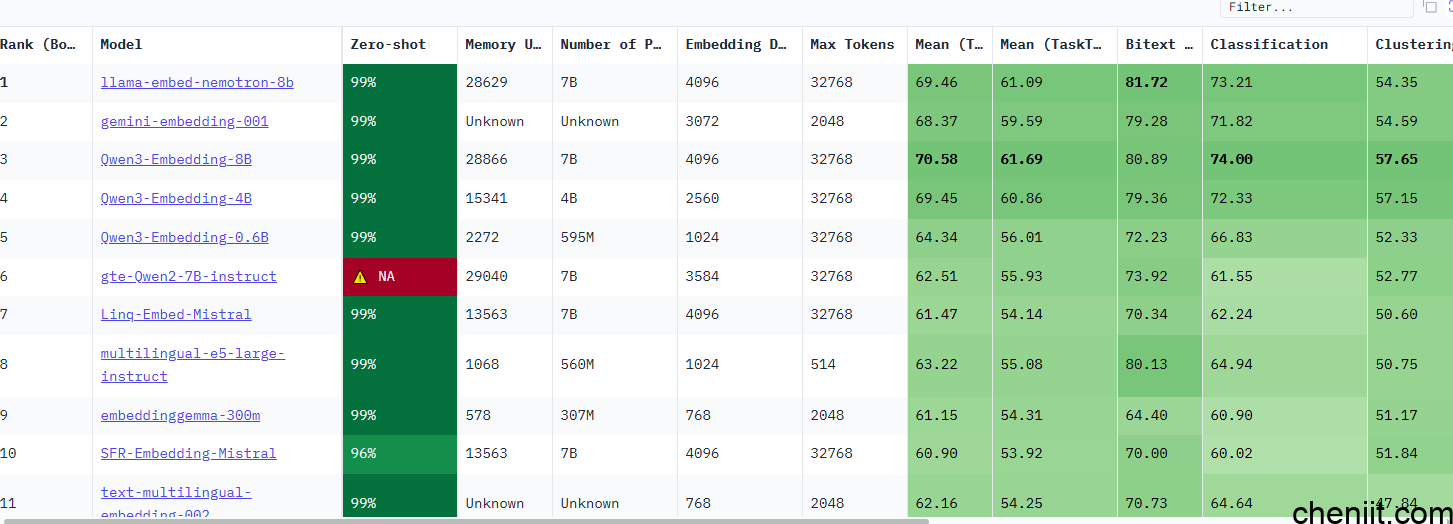
9.MTEB (Massive Text Embedding Benchmark)
简介:评测文本嵌入模型,覆盖 56 个数据集、112 种语言,是主流 embedding 标准。
网址:https://huggingface.co/spaces/mteb/leaderboard
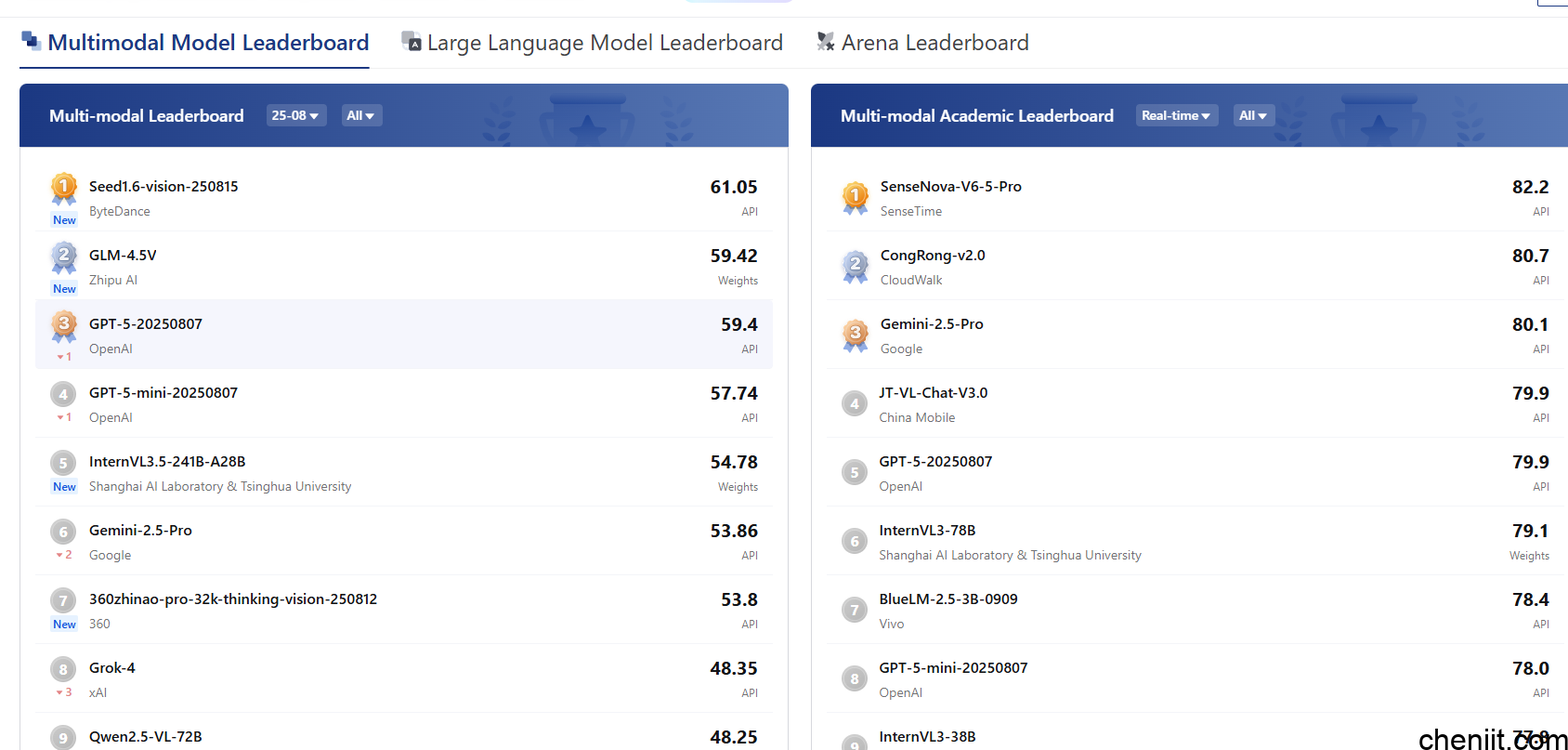
10.OpenCompass: CompassRank
简介:亚洲最具代表性的多语言评测平台,支持合规性与中文任务测试。
网址:https://rank.opencompass.org.cn/home
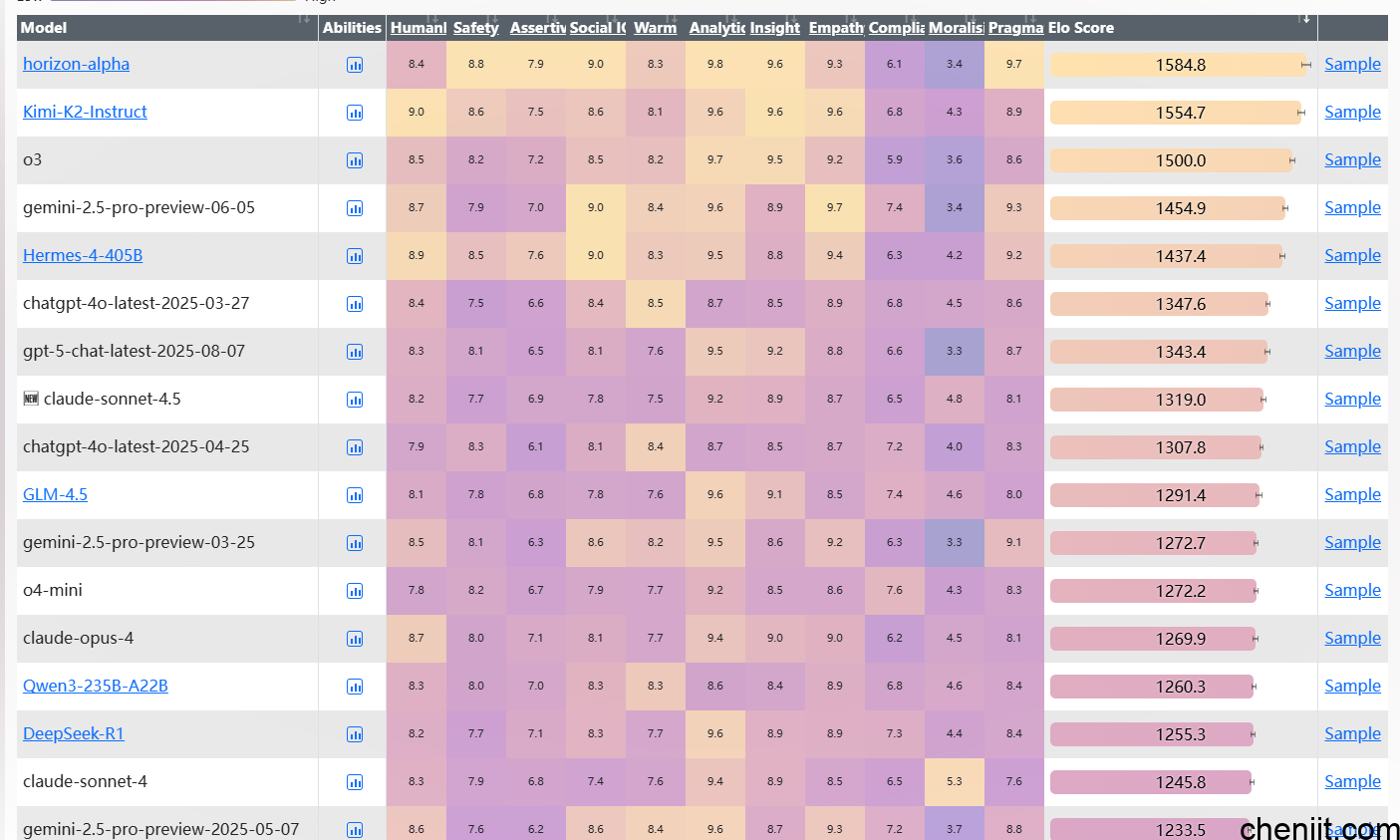
11.EQ-Bench
简介:评估模型的情绪智能与共情能力,基于 170 + 提示。
网址:https://eqbench.com/
12.Berkeley Function-Calling Leaderboard
简介:比较模型在结构化输出与函数调用方面的表现,聚焦企业 copilot 应用。
网址:https://gorilla.cs.berkeley.edu/leaderboard.html

13.CanAiCode Leaderboard
简介:针对代码生成模型的专项评测,突出小型模型的 text-to-code 能力。
网址:https://huggingface.co/spaces/mike-ravkine/can-ai-code-results
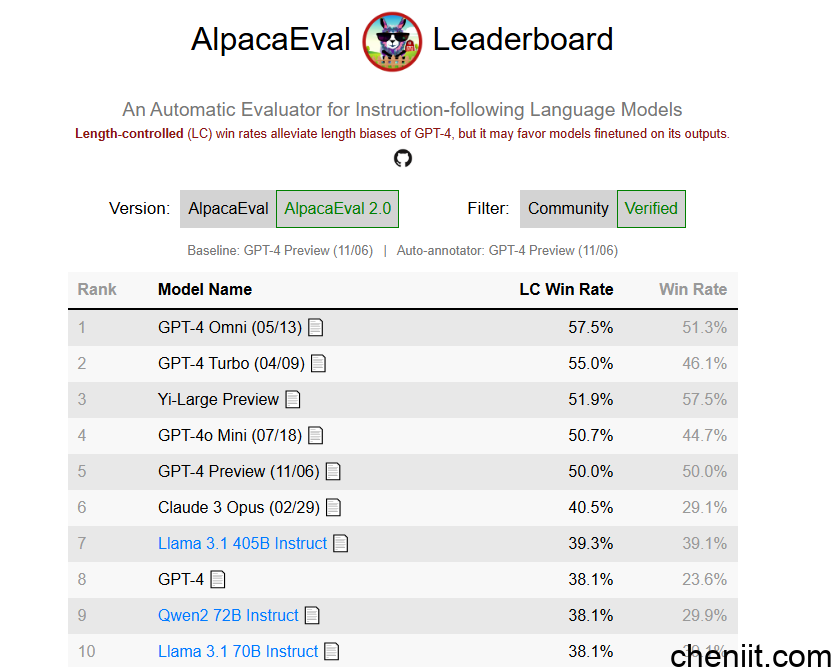
14.AlpacaEval Leaderboard
简介:评测指令跟随能力,以 GPT-4 输出作为对照,快速衡量中小模型质量。
网址:https://tatsu-lab.github.io/alpaca_eval/